Jak działa serwer WWW i w jaki sposób udostępnia stronę internetową użytkownikom

Serwer WWW stanowi fundament współczesnego internetu, umożliwiając publikację oraz udostępnianie zasobów sieciowych w formie stron internetowych. Jego rola sprowadza się do odbioru żądań przesyłanych przez przeglądarki, przetworzenia ich zgodnie z określonymi protokołami oraz zwrócenia odpowiedzi w postaci kodu HTML, stylów CSS czy plików multimedialnych. Dzięki precyzyjnej konfiguracji i optymalizacji, serwer staje się niezawodnym elementem łańcucha, który łączy twórców treści z odbiorcami na całym świecie.
Podstawy działania serwera WWW
Na samym początku warto zrozumieć, że serwer WWW to specjalistyczne oprogramowanie oraz sprzęt, który stale nasłuchuje na określonym porcie sieciowym (domyślnie port 80 dla HTTP i port 443 dla HTTPS). Po otrzymaniu sygnału od klienta – najczęściej przeglądarki internetowej – analizuje otrzymane żądanie (request), by następnie wybrać odpowiedni zasób do wysłania w odpowiedzi (response).
Kluczowymi elementami architektury serwera są:
- Procesy robocze (ang. worker processes) obsługujące napływające połączenia,
- Moduły rozszerzeń odpowiedzialne za obsługę języków skryptowych (PHP, Python, Ruby),
- System plików lub magazyn obiektowy, w którym przechowywane są pliki strony,
- Bufor pamięci podręcznej (cache) przyspieszający dostęp do najczęściej wyświetlanych zasobów.
Proces obsługi żądania użytkownika
Analiza żądania rozpoczyna się od rozpoznania metody HTTP (np. GET, POST, PUT), ścieżki zasobu oraz nagłówków. Dopiero na tej podstawie serwer podejmuje decyzję, czy wystarczy przesłać plik statyczny, czy też wywołać interpreter odpowiedniego języka programowania. W sytuacjach wymagających dynamicznej generacji treści konieczne jest uruchomienie silnika skryptowego, który zbuduje dokument HTML, a następnie zwróci go klientowi.
W celu zapewnienia wysokiej dostępności i minimalizacji opóźnień stosowane są często zaawansowane mechanizmy, takie jak oferuje hostido.pl , wydajne procesory i automatyczną kopię zapasową, co umożliwia szybką obsługę dużego ruchu i ochronę przed awariami. Dzięki temu nawet w szczytowych momentach serwer jest w stanie równocześnie przetwarzać setki tysięcy zapytań.
Rola protokołu HTTP w komunikacji
Protokół HTTP (HyperText Transfer Protocol) definiuje zasady wymiany danych między klientem a serwerem. Obejmuje on określenie metod żądań, kodów odpowiedzi (np. 200 OK, 404 Not Found, 500 Internal Server Error) oraz format nagłówków. To właśnie nagłówki decydują o sposobie przesyłania danych: czy strona ma być buforowana, jak długi jest ważny certyfikat czy jakie typy danych mogą być akceptowane.
Wersja HTTP/1.1 wprowadziła trwałe połączenia (keep-alive), co znacząco obniżyło narzut czasowy na wielokrotne zestawianie sesji TCP. Z kolei HTTP/2 dodał kompresję nagłówków i multiplitykację strumieni, pozwalając na równoległe pobieranie wielu zasobów w ramach jednej sesji, a HTTP/3, korzystając z protokołu QUIC, minimalizuje opóźnienia związane z nawiązywaniem połączenia.
Przechowywanie i udostępnianie plików strony
W zależności od skali projektu, zasoby strony mogą być umieszczone na: serwerach fizycznych, maszynach wirtualnych lub w ramach platform chmurowych. Ważne jest, aby system plików charakteryzował się niskim czasem dostępu oraz możliwością obsługi dużej liczby równoczesnych operacji odczytu i zapisu. W praktyce wykorzystuje się dyski SSD, często skonfigurowane w macierze RAID dla zwiększenia szybkości i niezawodności.
Do przyspieszania dostarczania statycznych plików stosuje się sieci CDN (Content Delivery Network), które replikują zasoby w węzłach rozsianych po różnych kontynentach. Dzięki temu każdy użytkownik otrzymuje odpowiedzi z geograficznie najbliższego serwera, co skraca czas ładowania elementów strony takich jak grafiki, arkusze stylów czy skrypty JavaScript.
Znaczenie konfiguracji serwera dla wydajności
Prawidłowa konfiguracja limitów pamięci, liczby procesów roboczych i ustawień buforowania przekłada się bezpośrednio na szybkość i stabilność działania serwera. Niewłaściwe dopasowanie tych parametrów może prowadzić do przeciążenia CPU lub wyczerpania dostępnej pamięci, skutkując błędami krytycznymi i długimi czasami odpowiedzi.
Dodatkowo istotna jest optymalizacja warstwy sieciowej – wykorzystanie kompresji GZIP, ustawienie nagłówków Expires oraz ETag czy wprowadzenie mechanizmów load balancing w klastrze serwerów. Dzięki temu możliwe jest równomierne rozłożenie ruchu i lepsze wykorzystanie dostępnych zasobów.
W kontekście SEO, wysoka wydajność strony przekłada się na pozytywne oceny algorytmów wyszukiwarek, co oznacza lepszą widoczność w wynikach organicznych.
Bezpieczeństwo i zarządzanie dostępem na serwerze
Ochrona zasobów strony internetowej przed nieautoryzowanym dostępem wymaga wdrożenia mechanizmów uwierzytelniania oraz autoryzacji. Stosowanie certyfikatów SSL/TLS zapewnia szyfrowanie przesyłanych danych, a konfiguracja firewalla pozwala na filtrowanie niepożądanych pakietów sieciowych. Ważne jest także regularne aktualizowanie oprogramowania serwera, aby eliminować podatności.
Zarządzanie dostępem obejmuje nadawanie minimalnych uprawnień użytkownikom systemu plików oraz ograniczanie możliwości uruchamiania niezweryfikowanego kodu. Częstą praktyką jest również wdrażanie systemu IDS/IPS, który monitoruje ruch w poszukiwaniu anomalii i w razie potrzeby automatycznie blokuje złośliwe próby ataku.
Dodatkowym zabezpieczeniem jest tworzenie regularnych kopii zapasowych oraz testowanie procedur przywracania danych, co w razie awarii lub ataku pozwala szybko przywrócić pełną funkcjonalność serwisu.

Ostatnie Artykuły

Dwa wieczory jazzu pod drzewami. Blue Note przenosi koncerty do parku

Autobus Polskiej Stolicy Kultury przyjedzie do Poznania z programem pełnym sztuki

Cztery mecze młodych reprezentacji w Poznaniu. Polska zagra z Czechami
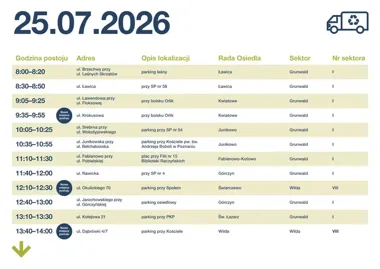
Sześć nowych punktów Gratowozu w Poznaniu. Znamy sobotni rozkład

150 zawodników przy szachownicach. Mistrzostwa powiatu w Dworze Skrzynki

Popowe hity przy tysiącu świec. Backstreet Boys i Spice Girls w nowej odsłonie

Niegrzeczny chłopiec trafi do profesora. Teatr Nemno pokaże „Gburka”

Święty Marcin na nowo. Jubileuszowe spacery po Poznaniu

Rockowe hity zabrzmią przy tysiącu świec. Zagra kwartet smyczkowy

Marionetki pokażą swoje sekrety podczas warsztatów w Poznaniu

Żużel, nocne pływanie i kąpieliska. Sportowy weekend w Poznaniu

Kontenery w Kiekrzu skrywały nielegalny tytoń wart miliony

Nad wodą chwila brawury może skończyć się tragedią. Ratownicy ostrzegają

Welshly Arms w Poznaniu - gdy stadion mieści się w klubie
Przydatne dane teleadresowe
- Delegatura NIK w Poznaniu - kontakt, adres, zasięg kontroli
- Prokuratura Rejonowa Poznań-Wilda - kontakt, dyżur i zasady przyjęć
- PKS Poznań S.A. - kontakt, rozkład jazdy, bilety i wynajem autobusów
- Poradnia Psychologiczno-Pedagogiczna nr 5 Poznań-Stare Miasto - kontakt, oferta, zapisy
- Regionalna Dyrekcja Lasów Państwowych w Poznaniu - kontakt, nadleśnictwa, drewno opałowe, zezwolenia
- Parafia NMP z La Salette w Poznaniu - msze, kancelaria, sakramenty